Turing Test Applied to an Artist
When looking at the visual works that machines are producing in the category known as GANs or GANs (generative adversarial networks), the first thing that jumps out is that, in a way, it’s a Turing test applied to art. But what makes this connection obvious? So let’s start by thinking about what these adversarial networks do. A machine undergoes an unsupervised (human-supervised) learning process based on a series of multi-layered algorithms, where AI (artificial intelligence) is implemented by the opposition of two neural networks that play against each other, without cooperating, until one network convinces the other of something. This something can be reality, human emotional capacity, or simply a photo.
Let’s take the example of photos. If a machine, in this zero-sum game, manages to get a human to see a photo (synthetic or synthetic) and believe it’s real, deceiving the human’s discrimination criteria (part of the algorithm), the machine sees a positive in the production of technical images representative of natural reality. Phew! It sounds similar to the curatorial processes at art fairs that govern art markets. But deceiving a human, the way Richard Estes often did, puts the observer, the viewer, or simply the algorithm at odds; generating a technical interpretation of the image from photographic fragments makes the process with RGAs very interesting.
If, for example, on Twitter, under the hashtag #BigGan, you can see not only the images produced by these networks, but, like me, you were perplexed to see the artistic potential the machine acquires; and with this, explore a new state of the art and its relationship with representation. But if we transpose the experiment, and the human observer is not an ordinary person, but a curator or gallery owner, in which we assign the artistic value of a technical image, the experiment becomes much more interesting. Richard Estes’s value was his ability to deceive the viewer with the photorealism of his paintings. Generative adversarial networks are producing images representative of reality that deceive the human eye, such as these:

Synthetic images produced by a neural network, by statistically analyzing and datatifying the order of pixels in an image based on the comparative exercise of a sort of logical form of the photographic image, manage to make us believe that this is the image of a wolf, a mushroom, a soap bubble, and a delicious dessert that I don’t think has a name.

Seeing this type of synthetic image generated by competing networks is very powerful. But understanding the cognitive process and computational capacity required to deceive us with these simulations of reality is important to explore. The paper, Large Scale GAN Training for High Fidelity Natural Image Synthesis, by Andrew Brock in collaboration with Jeff Donahue and Karen Simonyan, opens the debate on this type of construction of representations of reality and is being reviewed for the ICLR Spring 2019 conference.
Now, if we take the images produced by these AIs to deceive their validating peer, we find much more powerful images that redefine the photographic process and the reinvention it entails in synthetic image creation.
The construction of these realistic images discards thousands of simulations that are not validated. But if we see these discarded images, the artistic horizon expands with an artistic spectrum unsuspected by researchers.

These images could easily be read as an artistic exploration of a young, artificial talent, on whom Charles Saatchi focused his attention. The complexity of the representational error allows for the interpretation of something obscure in the construction of the image, and this gesture could have very powerful artistic value. Or at least I imagine Saatchi would see it that way. This Glamcut series by the Chapman brothers competes, in an artistic sense, with the re-signification of reality through the play of art.

If we take a brief look at #BigGAN, we’ll find a gallery of images that transitions from the bizarre to the abstract with the fluidity of any contemporary artist working with technical image composition. In his book “The Universe of Technical Images,” Vilém Flusser warned us of a new visual phenomenon, which we see today in the synthesis of these images, but which the Czech-Brazilian philosopher had been seeing since the 1980s. For Flusser, the phenomenon of the experience of the world, after linear texts, was the advent of an image encoded by devices or by the apparatus, which would take us to the limits of history and the experience of a post-writing graphic. The synthetic creation of electronic images launched his discourse into a new imaginative environment that witnessed the cultural transition from an alphanumeric society to the advent of the digital.
If we return to the perspective of gallery owner Charles Saatchi and the way his eschatological curation has reinterpreted not only advertising but also contemporary art, we might consider valuing the image production of these neural networks as artistic creations in the British style that Charles Saatchi imbued into contemporary art.
In the paper mentioned at the beginning of the work, the authors propose a simulation model (BigGAN) with modifications focused on the following aspects:
· Scale: Scale is essential to improve image understanding and interpretation, which is why they used the orthogonal regularization technique for the generating AI.
· Robustness: This orthogonal regularization enhances the “truncation trick,” where intervals in the image’s latent space are truncated to achieve greater image fidelity.
· Stability: The instabilities of BigGANs are characterized in their study, so solutions to image stability are proposed that generate very satisfactory results.
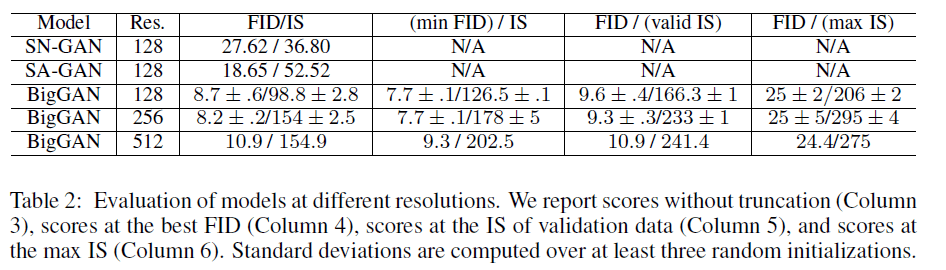
The research works with three resolutions: 128×128, 256×256, and 512×512; which, despite being apparently low, are incredibly complex to render, and the machine’s cognitive capacity must be high-performance. In these simulations, the realistic results are astonishing and surely satisfy the common man when playing with photographic representation, as Estes did in his painting; but thinking about the creative possibility in the field of art gives added value to the possibilities that open up in the world of artificial artistic creation. Thinking about this Turing Test applied to a curator would surely make these synthetic images created by the system of generative adversarial networks generate a creative trend in non-human art and would explode under our noses the re-signification of the value of art in digital culture (cyberculture).
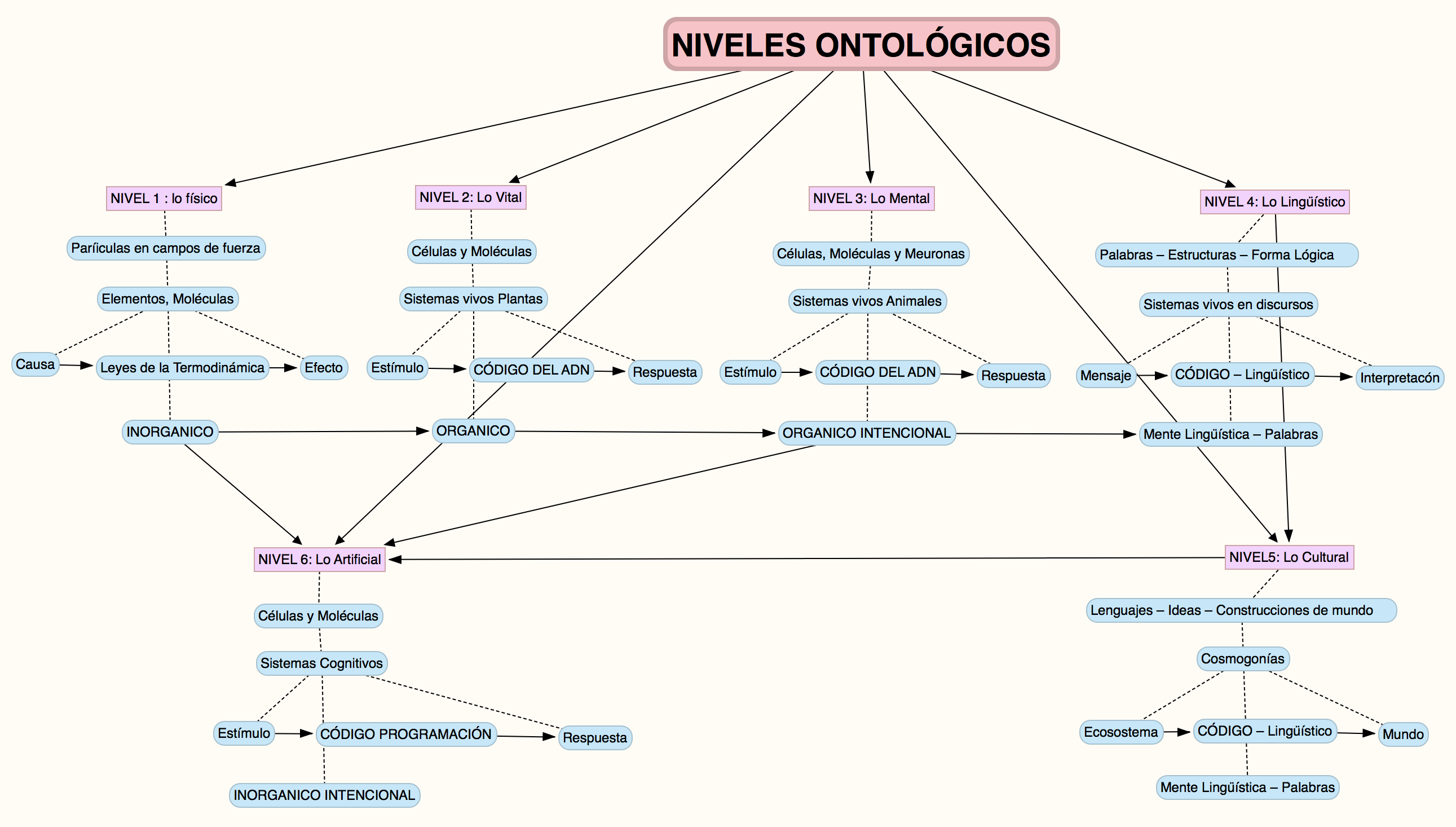
Without a doubt, within the field of advanced research topics, the potential of neural networks and their creative capacity will be part of my research project, within the framework of the proposal for an Artificial Ontology that relates technical objects to the stewardship of the world, and that, at the dawn of technology we explore in the seminars, propels the search for new territories of metaphysical thought. Thinking at the artificial level, in terms of artistic creation, aims to accompany the course of my doctoral research, exploring the limits of AI’s cognitive capacity in the emotional interpretation that governs the realm of human relations. Navigating these limits of knowledge and the mutation of the symbolic in terms of a new sign economy will be the central axis and guiding principle of the path that is just beginning. An ontology of technical objects, of their creative capacity and insertion into the meaning of the world, brings these modes of inhabiting the image to a very stimulating terrain of work in thought; and similarly imposes a fundamental challenge when it comes to constructing a thought of the advent of the future of our species and planet in a new Noosphere integrated with the machine, where the value of life is revalidated with the technological environment into which we, as linguistic and self-conscious beings, are throwing ourselves.

